Wie man Slither verwendet, um Fehler in Smart Contracts zu finden
Wie man Slither verwendet
Das Ziel dieses Tutorials ist es zu zeigen, wie man Slither verwendet, um automatisch Fehler in Smart Contracts zu finden.
- Installation
- Verwendung der Befehlszeile
- Einführung in die statische Analyse: Kurze Einführung in die statische Analyse
- API: Beschreibung der Python-API
Installation
Slither erfordert Python >= 3.6. Es kann über pip oder mit Docker installiert werden.
Slither über pip:
pip3 install --user slither-analyzerSlither über Docker:
docker pull trailofbits/eth-security-toolboxdocker run -it -v "$PWD":/share trailofbits/eth-security-toolboxDer letzte Befehl führt die eth-security-toolbox in einem Docker-Container aus, der Zugriff auf Ihr aktuelles Verzeichnis hat. Sie können die Dateien von Ihrem Host aus ändern und die Tools für die Dateien aus dem Docker-Container heraus ausführen.
Führen Sie innerhalb von Docker Folgendes aus:
cd /shareEin Skript ausführen
Um ein Python-Skript mit Python 3 auszuführen:
python3 script.pyBefehlszeile
Befehlszeile im Vergleich zu benutzerdefinierten Skripten. Slither wird mit einer Reihe vordefinierter Detektoren geliefert, die viele häufige Fehler finden. Der Aufruf von Slither über die Befehlszeile führt alle Detektoren aus, es sind keine detaillierten Kenntnisse der statischen Analyse erforderlich:
slither project_pathsZusätzlich zu den Detektoren verfügt Slither über Code-Review-Funktionen durch seine Printers (opens in a new tab) und Tools (opens in a new tab).
Verwenden Sie crytic.io (opens in a new tab), um Zugriff auf private Detektoren und die GitHub-Integration zu erhalten.
Statische Analyse
Die Funktionen und das Design des statischen Analyse-Frameworks Slither wurden in Blogbeiträgen (1 (opens in a new tab), 2 (opens in a new tab)) und einem wissenschaftlichen Artikel (opens in a new tab) beschrieben.
Statische Analyse gibt es in verschiedenen Ausprägungen. Sie wissen wahrscheinlich, dass Compiler wie clang (opens in a new tab) und gcc (opens in a new tab) auf diesen Forschungstechniken basieren, aber sie untermauern auch Tools wie Infer (opens in a new tab), CodeClimate (opens in a new tab), FindBugs (opens in a new tab) und Werkzeuge, die auf formalen Methoden basieren, wie Frama-C (opens in a new tab) und Polyspace (opens in a new tab).
Wir werden hier nicht erschöpfend auf statische Analysetechniken und Forscher eingehen. Stattdessen konzentrieren wir uns darauf, was nötig ist, um zu verstehen, wie Slither funktioniert, damit Sie es effektiver nutzen können, um Fehler zu finden und Code zu verstehen.
Code-Darstellung
Im Gegensatz zu einer dynamischen Analyse, die einen einzelnen Ausführungspfad betrachtet, berücksichtigt die statische Analyse alle Pfade auf einmal. Dazu stützt sie sich auf eine andere Code-Darstellung. Die beiden häufigsten sind der abstrakte Syntaxbaum (Abstract Syntax Tree, AST) und der Kontrollflussgraph (Control Flow Graph, CFG).
Abstrakte Syntaxbäume (AST)
ASTs werden jedes Mal verwendet, wenn der Compiler Code parst. Es ist wahrscheinlich die grundlegendste Struktur, auf der eine statische Analyse durchgeführt werden kann.
Kurz gesagt ist ein AST ein strukturierter Baum, bei dem normalerweise jedes Blatt eine Variable oder eine Konstante enthält und interne Knoten Operanden oder Kontrollflussoperationen sind. Betrachten Sie den folgenden Code:
1function safeAdd(uint a, uint b) pure internal returns(uint){2 if(a + b <= a){3 revert();4 }5 return a + b;6}Der entsprechende AST wird hier gezeigt:
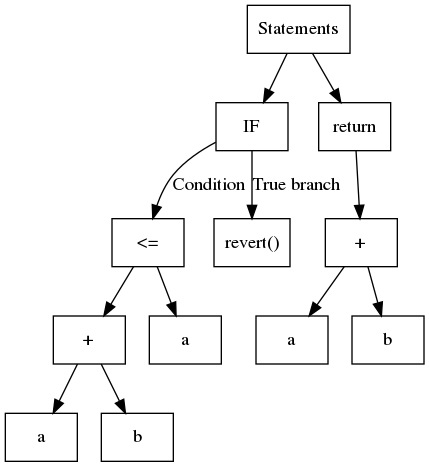
Slither verwendet den von solc exportierten AST.
Obwohl er einfach zu erstellen ist, ist der AST eine verschachtelte Struktur. Manchmal ist dies nicht am einfachsten zu analysieren. Um beispielsweise die vom Ausdruck a + b <= a verwendeten Operationen zu identifizieren, müssen Sie zuerst <= und dann + analysieren. Ein gängiger Ansatz ist die Verwendung des sogenannten Visitor-Patterns, das rekursiv durch den Baum navigiert. Slither enthält einen generischen Visitor in ExpressionVisitor (opens in a new tab).
Der folgende Code verwendet ExpressionVisitor, um zu erkennen, ob der Ausdruck eine Addition enthält:
1from slither.visitors.expression.expression import ExpressionVisitor2from slither.core.expressions.binary_operation import BinaryOperationType3
4class HasAddition(ExpressionVisitor):5
6 def result(self):7 return self._result8
9 def _post_binary_operation(self, expression):10 if expression.type == BinaryOperationType.ADDITION:11 self._result = True12
13visitor = HasAddition(expression) # expression ist der zu testende Ausdruck14print(f'The expression {expression} has a addition: {visitor.result()}')Kontrollflussgraph (CFG)
Die zweithäufigste Code-Darstellung ist der Kontrollflussgraph (CFG). Wie der Name schon sagt, handelt es sich um eine graphenbasierte Darstellung, die alle Ausführungspfade aufzeigt. Jeder Knoten enthält eine oder mehrere Anweisungen. Kanten im Graphen stellen die Kontrollflussoperationen dar (if/then/else, Schleife usw.). Der CFG unseres vorherigen Beispiels ist:
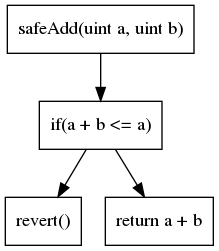
Der CFG ist die Darstellung, auf der die meisten Analysen aufbauen.
Es existieren viele weitere Code-Darstellungen. Jede Darstellung hat Vor- und Nachteile, je nachdem, welche Analyse Sie durchführen möchten.
Analyse
Die einfachste Art von Analysen, die Sie mit Slither durchführen können, sind syntaktische Analysen.
Syntaxanalyse
Slither kann durch die verschiedenen Komponenten des Codes und deren Darstellung navigieren, um Inkonsistenzen und Fehler mithilfe eines Mustererkennungs-ähnlichen Ansatzes zu finden.
Zum Beispiel suchen die folgenden Detektoren nach syntaxbezogenen Problemen:
-
Shadowing von Zustandsvariablen (opens in a new tab): Iteriert über alle Zustandsvariablen und prüft, ob eine davon eine Variable aus einem geerbten Vertrag überschattet (state.py#L51-L62 (opens in a new tab))
-
Falsche ERC20-Schnittstelle (opens in a new tab): Sucht nach falschen ERC20-Funktionssignaturen (incorrect_erc20_interface.py#L34-L55 (opens in a new tab))
Semantische Analyse
Im Gegensatz zur Syntaxanalyse geht eine semantische Analyse tiefer und analysiert die „Bedeutung“ des Codes. Diese Familie umfasst einige breit gefächerte Arten von Analysen. Sie führen zu leistungsfähigeren und nützlicheren Ergebnissen, sind aber auch komplexer zu schreiben.
Semantische Analysen werden für die fortschrittlichsten Schwachstellenerkennungen verwendet.
Datenabhängigkeitsanalyse
Eine Variable variable_a gilt als datenabhängig von variable_b, wenn es einen Pfad gibt, auf dem der Wert von variable_a durch variable_b beeinflusst wird.
Im folgenden Code ist variable_a abhängig von variable_b:
1// ...2variable_a = variable_b + 1;Slither verfügt dank seiner Zwischendarstellung (die in einem späteren Abschnitt besprochen wird) über integrierte Funktionen zur Datenabhängigkeit (opens in a new tab).
Ein Beispiel für die Nutzung von Datenabhängigkeiten findet sich im Detektor für gefährliche strikte Gleichheit (opens in a new tab). Hier sucht Slither nach einem strikten Gleichheitsvergleich mit einem gefährlichen Wert (incorrect_strict_equality.py#L86-L87 (opens in a new tab)) und informiert den Benutzer, dass er >= oder <= anstelle von == verwenden sollte, um zu verhindern, dass ein Angreifer den Vertrag in eine Falle lockt. Unter anderem betrachtet der Detektor den Rückgabewert eines Aufrufs von balanceOf(address) als gefährlich (incorrect_strict_equality.py#L63-L64 (opens in a new tab)) und verwendet die Datenabhängigkeits-Engine, um dessen Verwendung zu verfolgen.
Fixpunktberechnung
Wenn Ihre Analyse durch den CFG navigiert und den Kanten folgt, werden Sie wahrscheinlich bereits besuchte Knoten sehen. Zum Beispiel, wenn eine Schleife wie unten gezeigt vorliegt:
1for(uint i; i < range; ++i){2 variable_a += 13}Ihre Analyse muss wissen, wann sie anhalten soll. Hier gibt es zwei Hauptstrategien: (1) eine endliche Anzahl von Malen über jeden Knoten iterieren, (2) einen sogenannten Fixpunkt berechnen. Ein Fixpunkt bedeutet im Grunde, dass die Analyse dieses Knotens keine aussagekräftigen Informationen mehr liefert.
Ein Beispiel für die Verwendung eines Fixpunkts findet sich in den Reentrancy-Detektoren: Slither untersucht die Knoten und sucht nach externen Aufrufen sowie Schreib- und Lesezugriffen auf den Speicher. Sobald ein Fixpunkt erreicht ist (reentrancy.py#L125-L131 (opens in a new tab)), stoppt es die Untersuchung und analysiert die Ergebnisse, um anhand verschiedener Reentrancy-Muster zu prüfen, ob eine Reentrancy vorliegt (reentrancy_benign.py (opens in a new tab), reentrancy_read_before_write.py (opens in a new tab), reentrancy_eth.py (opens in a new tab)).
Das Schreiben von Analysen unter Verwendung einer effizienten Fixpunktberechnung erfordert ein gutes Verständnis dafür, wie die Analyse ihre Informationen weitergibt.
Zwischendarstellung
Eine Zwischendarstellung (Intermediate Representation, IR) ist eine Sprache, die für die statische Analyse besser geeignet sein soll als die Originalsprache. Slither übersetzt Solidity in seine eigene IR: SlithIR (opens in a new tab).
Das Verständnis von SlithIR ist nicht erforderlich, wenn Sie nur grundlegende Prüfungen schreiben möchten. Es ist jedoch nützlich, wenn Sie planen, fortgeschrittene semantische Analysen zu schreiben. Die SlithIR (opens in a new tab)- und SSA (opens in a new tab)-Printers helfen Ihnen zu verstehen, wie der Code übersetzt wird.
API-Grundlagen
Slither verfügt über eine API, mit der Sie grundlegende Attribute des Vertrags und seiner Funktionen untersuchen können.
Um eine Codebasis zu laden:
1from slither.slither import Slither2slither = Slither('/path/to/project')3
Verträge und Funktionen untersuchen
Ein Slither-Objekt hat:
contracts (list(Contract): Liste von Verträgencontracts_derived (list(Contract): Liste von Verträgen, die nicht von einem anderen Vertrag geerbt werden (Teilmenge von Verträgen)get_contract_from_name (str): Gibt einen Vertrag anhand seines Namens zurück
Ein Contract-Objekt hat:
name (str): Name des Vertragsfunctions (list(Function)): Liste von Funktionenmodifiers (list(Modifier)): Liste von Funktionenall_functions_called (list(Function/Modifier)): Liste aller internen Funktionen, die durch den Vertrag erreichbar sindinheritance (list(Contract)): Liste der geerbten Verträgeget_function_from_signature (str): Gibt eine Funktion anhand ihrer Signatur zurückget_modifier_from_signature (str): Gibt einen Modifikator anhand seiner Signatur zurückget_state_variable_from_name (str): Gibt eine Zustandsvariable anhand ihres Namens zurück
Ein Function- oder Modifier-Objekt hat:
name (str): Name der Funktioncontract (contract): der Vertrag, in dem die Funktion deklariert istnodes (list(Node)): Liste der Knoten, aus denen sich der CFG der Funktion/des Modifikators zusammensetztentry_point (Node): Einstiegspunkt des CFGvariables_read (list(Variable)): Liste der gelesenen Variablenvariables_written (list(Variable)): Liste der geschriebenen Variablenstate_variables_read (list(StateVariable)): Liste der gelesenen Zustandsvariablen (Teilmenge von variables_read)state_variables_written (list(StateVariable)): Liste der geschriebenen Zustandsvariablen (Teilmenge von variables_written)
Letzte Aktualisierung der Seite: 3. März 2026


